Mobile FingerPrint is very popular on both IOS and Android devices. But for a normal device, like the desktop browser, mobile browser. How can we distinguish user without cookie technology?
On the Internet, Nobody Knows You’re a Dog
To be honest, we can know you are cat or dog. This practice is trying to build a reinforcement fingerprint solution with latest HTML5, Android DeviceID SDK , Apple Device ID SDK, Google Firebase InstanceID SDK, GeoService without cookie. This article tries to figure out these questions,
- What’s the problem? What’s device fingerprint?
- Which kinds of attributes can identify a unique device?
- Algorithm of web fingerprinting
- finger print is not unique, a double HASH mechanism
- Make user agent readable in the backend.
- GeoService to recognize IP location.
- Send SMS or Email to customer
- Database schema design
- Simple System Architecture
1. What is finger printing? Which problem can it solve for us?
browser fingerprinting is the capability of a site to identify or re-identify a visiting user, user agent or device via configuration settings or other observable characteristics. — w3c
Fingerprinting Guidance for Web Specification is the draft, it can be used as a security measure (e.g. as means of authenticating the user), google and apple are using for user authentication and trust devices.Uniquely identifies and tracks every device that accesses your site. Fraud detection is the most usage, there are 3 types of fingerprinting of web,
- Passive fingerprinting is browser fingerprinting based on characteristics observable in the contents of Web requests, without the use of any code executing on the client side.
- Active fingerprinting, we also consider techniques where a site runs JavaScript or other code on the local client to observe additional characteristics about the browser.
- user agents and devices may also be re-identified by a site that first sets and later retrieves state stored by a user agent or device. This cookie-like fingerprinting allows re-identification of a user or inferences about a user in the same way that HTTP cookies allow state management for the stateless HTTP protocol.
2.Which kinds of characteristics can identify a unique device?
More characteristics and attributes, more accuracy, but respect Data Privacy Laws such as The Data Protection Directive in EU. This practice doesn’t use cookie technology, respect privacy for the customer, we use HASH algorithm to avoid collect user web information directly. In the end, user characteristics are only HASH in our database, it is deliberately difficult to reconstruct it. 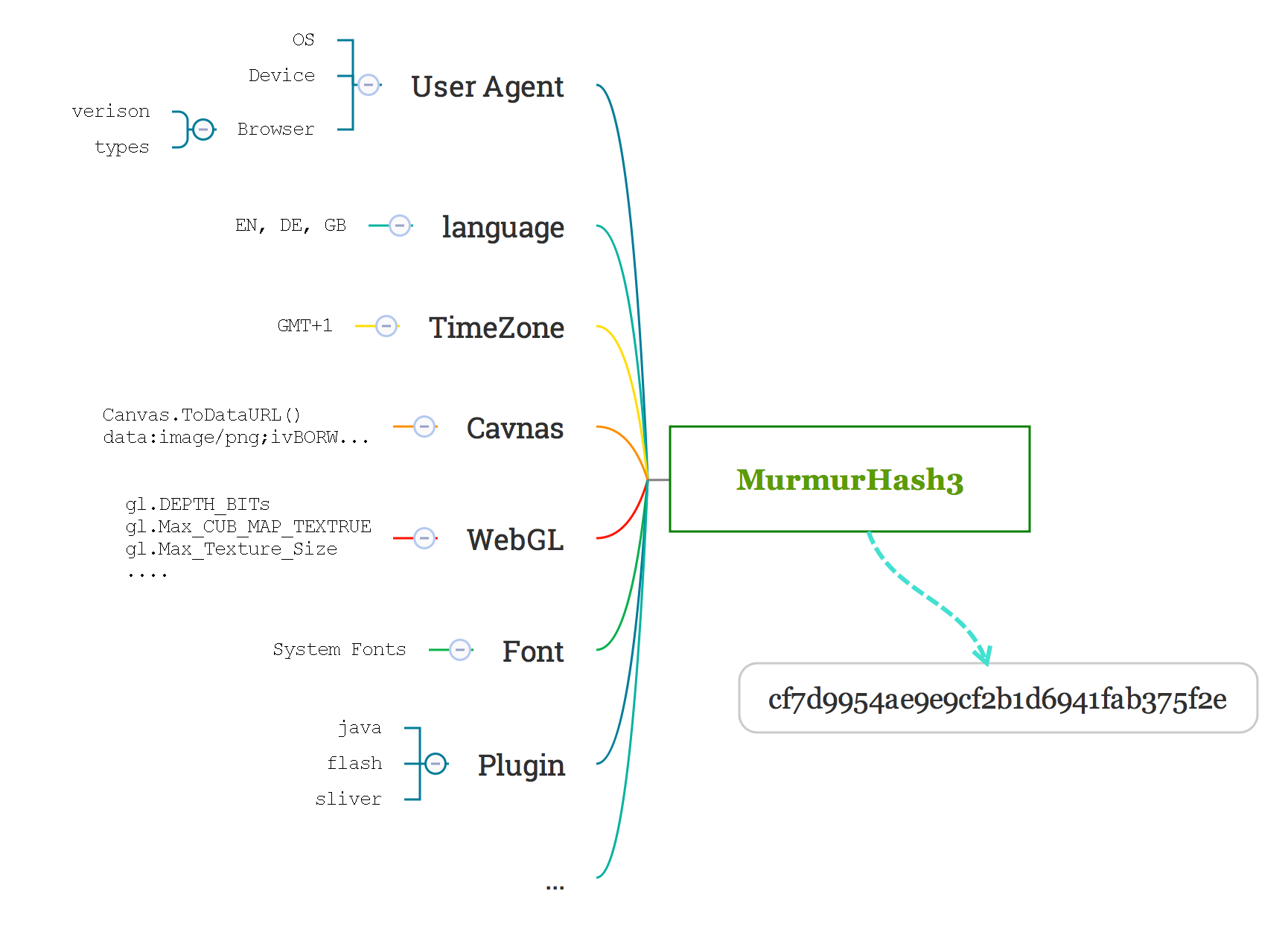
this is an example, in active mode, we can use a javascript library like fingerprintjs2 on the client side, to combine and encrypt users characteristics into a hash value. More detail of this library, please watch this video. https://player.vimeo.com/video/151208427, very simple and clear solution used in a lot of web site.
var fingerPrintingHash = null;
new Fingerprint2().get(function(result, components){
fingerPrintingHash = result;
console.log(result);
});
3. The algorithm of web fingerprinting
there is a famous paper, https://panopticlick.eff.org/static/browser-uniqueness.pdf
How unique is your browser?
this is the test unique of this paper, https://panopticlick.eff.org/. there is a simple algorithm can 94.2% of browsers with Flash or Java were unique in this sample.

If you need to know the detail, please read this paper, it depends on your collect characteristics, we don’t use supercookie and some plugins. If you in the simple solution, with some stable characteristics of your browser, you don’t need this algorithm, only 1 hash is the unique key.
4. finger printing is not unique, double HASH mechanism
Above this paragraph, there is only web system situation, but if the device is mobile. There are more opinions that can unique a device on the native mobile system. And this MD5 HASH can implement in server side.
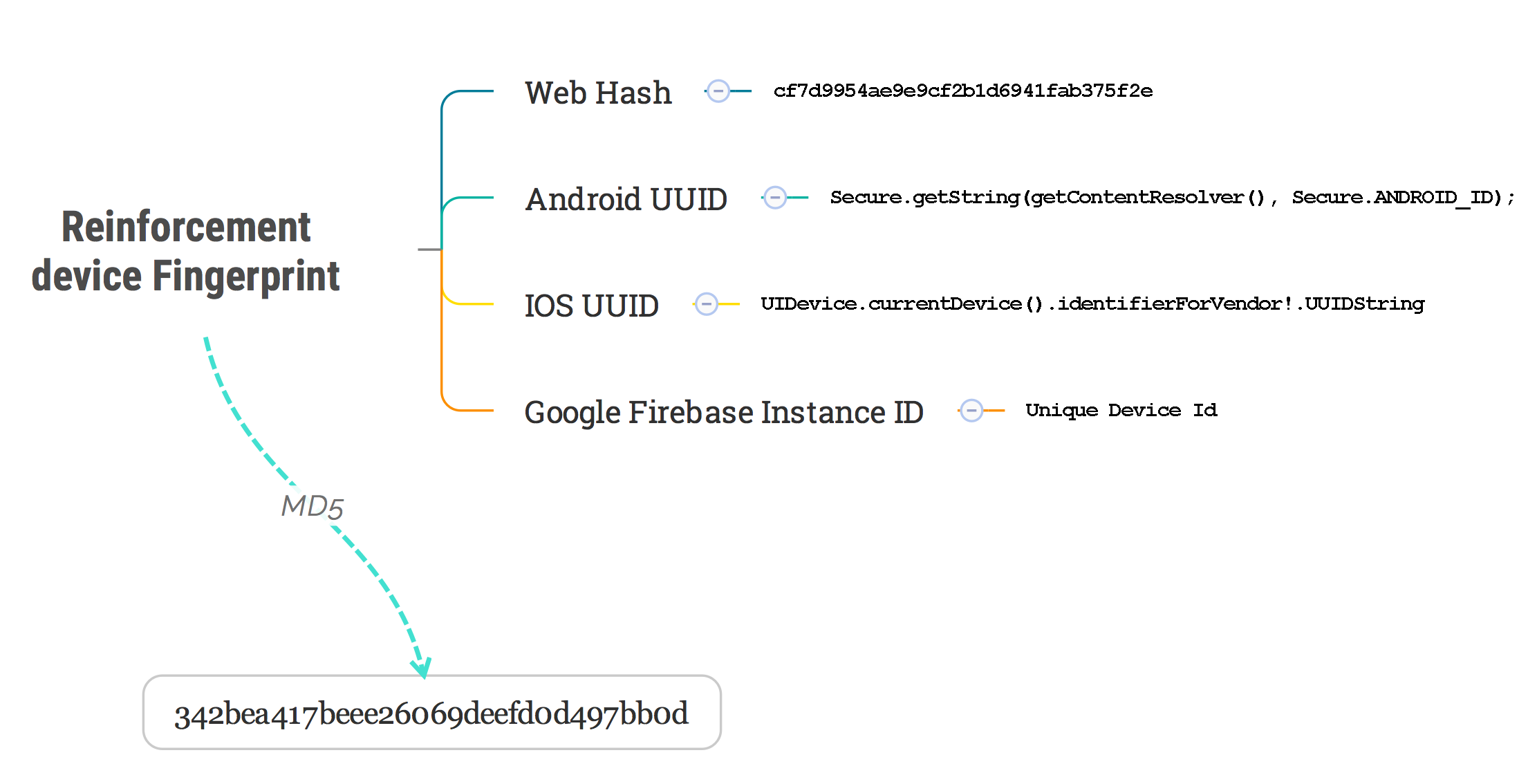
Both IOS and Android support UUID of their devices. In the old system, we can read IMEI (International Mobile Equipment Identity) directly, owing to the security consideration, IOS and Android stopped this access in the code. Otherwise, it is quite a useful information, you can use *#06# to call your phone to find it. For example, https://support.apple.com/en-us/HT204073.
String androidId = Secure.getString(getContentResolver(), Secure.ANDROID_ID);
https://developer.android.com/reference/android/provider/Settings.Secure.html#ANDROID_ID
let device_id = UIDevice.currentDevice().identifierForVendor?.UUIDString
https://developer.apple.com/documentation/uikit/uidevice
google, Firebase Instance ID provides a unique identifier for each app instance and a mechanism to authenticate and authorize actions. For example FCM messages in push notification usage. In fact, FCM also provided device token id to unique each device to push notification. It supports Web, Android, IOS platform.
FirebaseInstanceId.getInstance().getToken();
FirebaseInstanceId.getInstance().getId();
5. Make UserAgent readable
user agent information is in HTTP request like
Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Mobile Safari/537.36
We have to split and sperate into device, os, browser etc.. with version. there are some easy libraries to make it readable for developers.
http://uadetector.sourceforge.net/, you can use get os, get device, get web browser easily.
<dependency>
<groupId>net.sf.uadetector</groupId>
<artifactId>distribution</artifactId>
<version>2014.10</version>
</dependency>
|
UserAgentStringParser parser = UADetectorServiceFactory.getResourceModuleParser();
ReadableUserAgent agent = parser.parse(request.getHeader("User-Agent"));
in python, you can
pip install user_agents
readAgent = user_agents.parse("Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T)")
os = readAgent.os.family + ", " + readAgent.os.version_string
device = readAgent.device.family + ", " + readAgent.device.brand
6. GeoService to convert IP into a location and recognize IP proxy.
there are many services provided easy and powerful IP geo service, like maxmind, there is online service we can call directly with the license. java python, ect. SDK and API link here
pip install geoip2
import geoip2.webservice
def decodegeo(self):
country, state, city = None, None, None
try:
self.geoservice = geoip2.webservice.Client("userId", 'license token')
response = self.geoservice.insights("5.146.199.100")
country = response.country.name
state = response.subdivisions.most_specific.name
city = response.city.name
except Exception, e:
logger.error(e)
return country, state, city
in fact, there is fraud service from maxmind https://www.maxmind.com/en/minfraud-services, you also can try.
6. Send SMS or Email or push notification to customer when new login into the system.
we can use a simple SMTP library to send an email to the customers directly, but in current could world, you can use AMAZON SES or SNS.
http://docs.aws.amazon.com/zh_cn/ses/latest/DeveloperGuide/send-using-sdk-python.html
pip install boto3
import boto3
# Replace sender@example.com with your "From" address.
# This address must be verified with Amazon SES.
sender = "sender@example.com"
# Replace recipient@example.com with a "To" address. If your account
# is still in the sandbox, this address must be verified.
recipient = "recipient@example.com"
# If necessary, replace us-west-2 with the AWS Region you're using for Amazon SES.
awsregion = "us-west-2"
# The subject line for the email.
subject = "Amazon SES Test (SDK for Python)"
# The HTML body of the email.
htmlbody = """<h1>Amazon SES Test (SDK for Python)</h1><p>This email was sent with
<a href='https://aws.amazon.com/ses/'>Amazon SES</a> using the
<a href='https://aws.amazon.com/sdk-for-python/'>AWS SDK for Python (Boto)</a>.</p>"""
# The email body for recipients with non-HTML email clients.
textbody = "This email was sent with Amazon SES using the AWS SDK for Python (Boto)"
# The character encoding for the email.
charset = "UTF-8"
# Create a new SES resource and specify a region.
client = boto3.client('ses',region_name=awsregion)
# Try to send the email.
try:
#Provide the contents of the email.
response = client.send_email(
Destination={
'ToAddresses': [
recipient,
],
},
Message={
'Body': {
'Html': {
'Charset': charset,
'Data': htmlbody,
},
'Text': {
'Charset': charset,
'Data': textbody,
},
},
'Subject': {
'Charset': charset,
'Data': subject,
},
},
Source=sender,
)
# Display an error if something goes wrong.
except Exception as e:
print "Error: ", e
else:
print "Email sent!"
Send SMS to user phone
import boto3
sns = boto3.client('sns')
number = '+17702233322'
sns.publish(PhoneNumber = number, Message='example text message' )
If you need advanced notification and communication with customer, using twillio is another good choice, https://www.twilio.com/
8. Database schema design
this schema is MVP of the device identity, there are 2 HASH, web_hash_signature and firebase_device_token token is the unique key. to simplify, MD5(web_hash_signature + firebase_device_token) is also solution of Reinforcement.
CREATE TABLE `device` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(32) NOT NULL,
`user_login_name` varchar(32) NOT NULL,
`email` varchar(50) NOT NULL,
`os` varchar(32) NOT NULL,
`date` datetime NOT NULL,
`device` varchar(32) NOT NULL,
`country` varchar(32) NOT NULL,
`state` varchar(32) NOT NULL,
`web_hash_signature` varchar(64) NOT NULL,,
`firebase_device_token` varchar(200) NOT NULL,
`phonenumber` varchar(45) NOT NULL,
`ip` varchar(15) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `signature_UNIQUE` (`web_hash_signature`),
UNIQUE KEY `devicetoken_UNIQUE` (`firebase_device_token`),
UNIQUE KEY `phonenumber_UNIQUE` (`phonenumber`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
Then you can have almost basic fields to send google or apple or Airbnb login notification email. This is an example of airbnb login notification email, they need, country, state, city, device, os, time data.

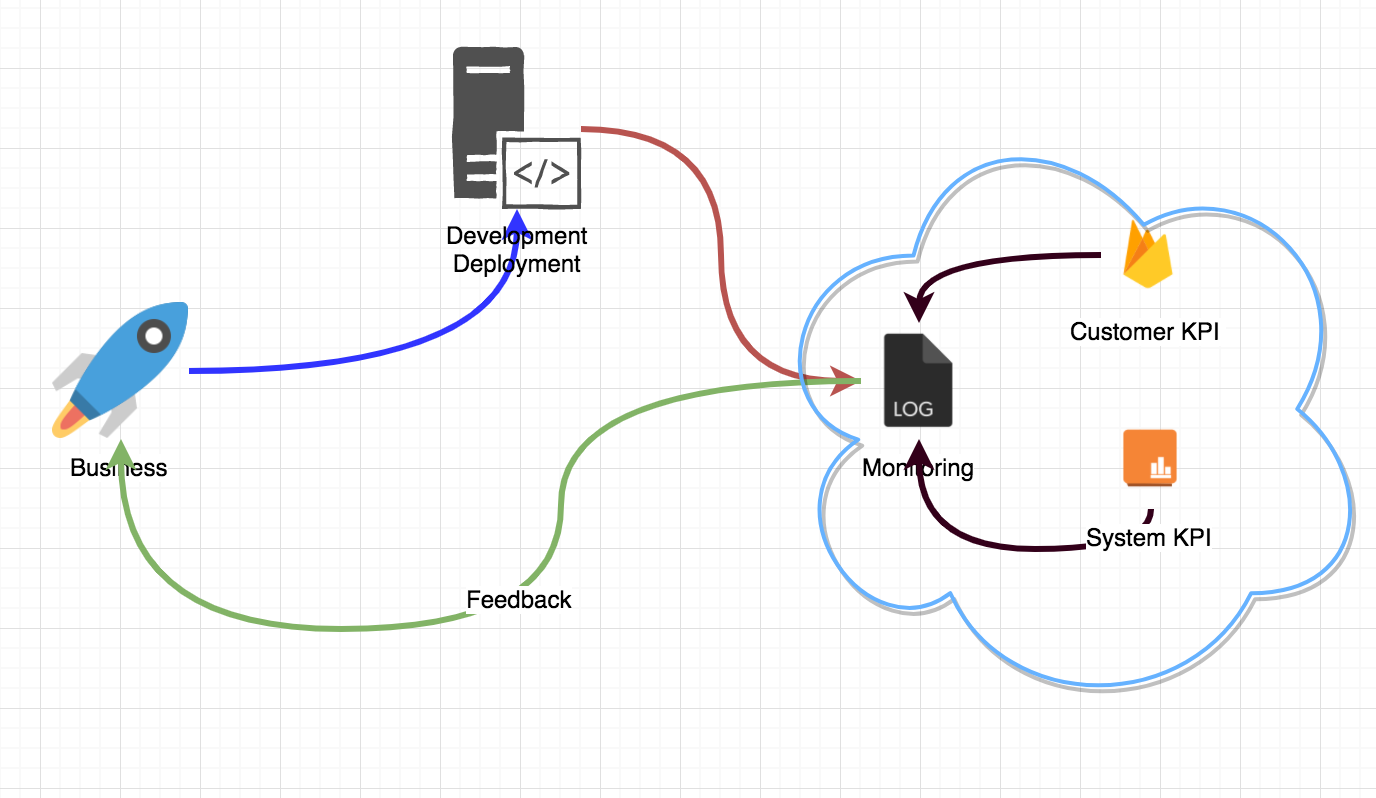
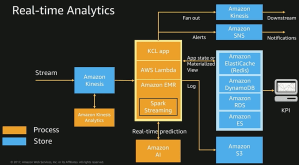
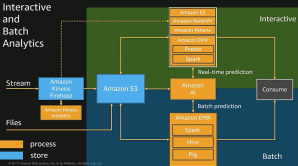
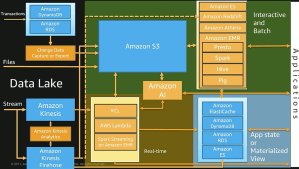
9. Simple System Architecture
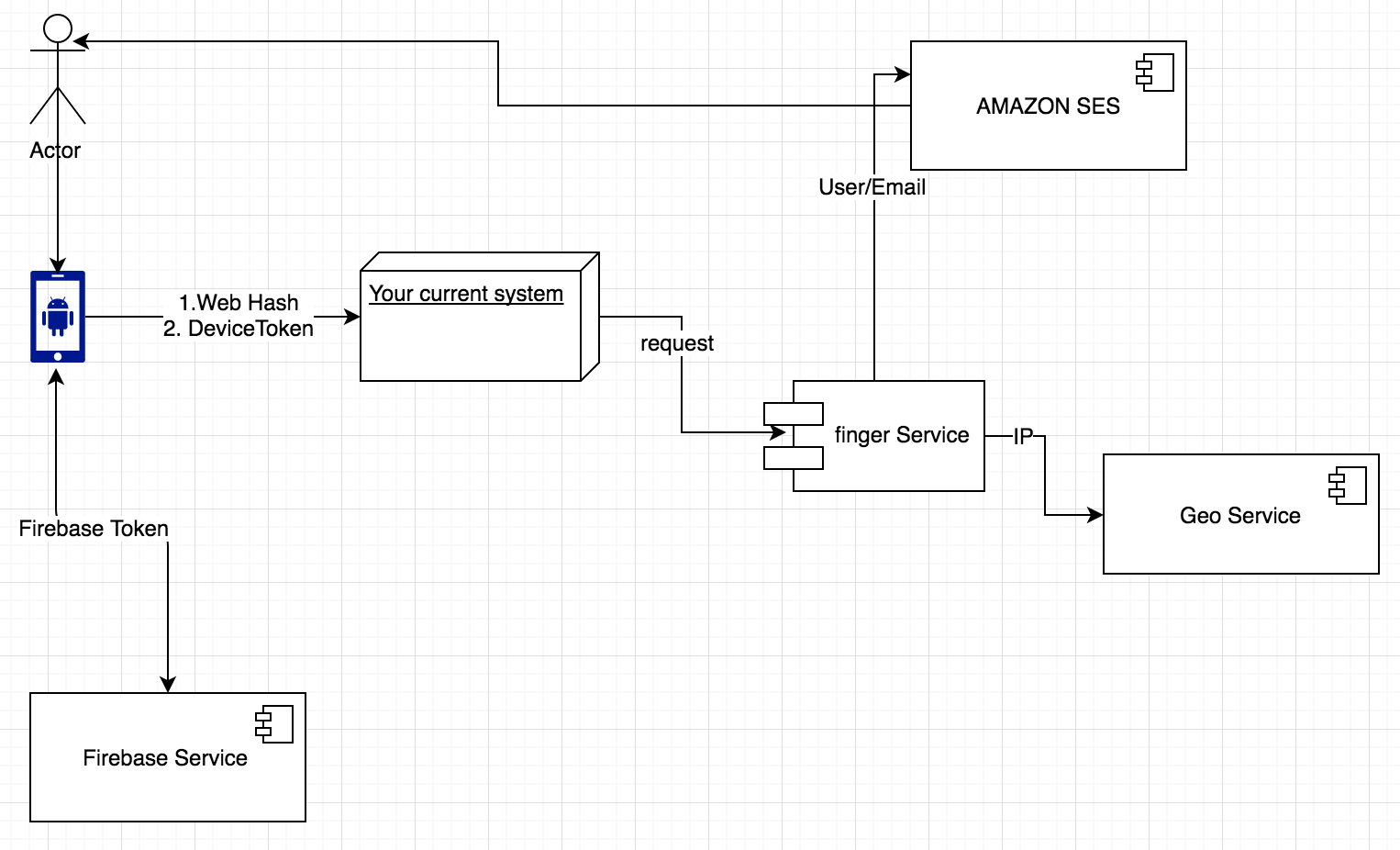
Summary, it is a practice and solution in my web and mobile system to identify the customer to avoid fraud login in the first step. Some problems should consider, like performance design like cache mechanism, web HASH based the stable characteristics (exclude browser version which customers always changing) in the future, invalidate session or token function in web system.





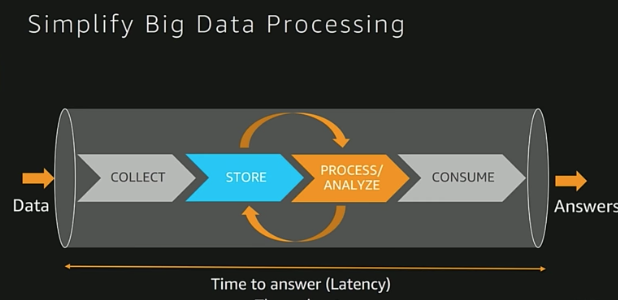
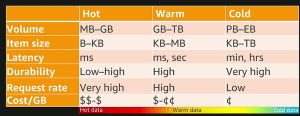

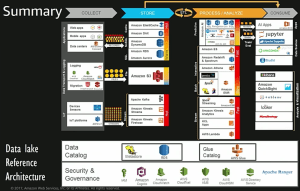
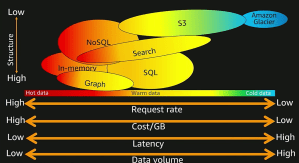 Amazon Components Compare in data store
Amazon Components Compare in data store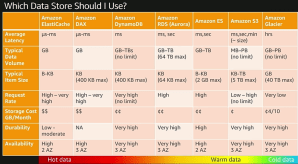



 Automation is the king
Automation is the king