
Don’t repeat yourself
https://en.wikipedia.org/wiki/Don%27t_repeat_yourself
Using Gitlab CI/CD and Github actions pipeline makes workflow for a single project quickly. There is always a pipeline file like .gitlab or .github/workflows in an individual project. But each developer or team need to maintain and update it regularly when there are bugs or updates.
In a big organization, there would be better to have a centralized team (e.g., Cloud Platform, Performance & Reliability Engineering, Engineering Tools) to develop standard tooling and infrastructure to solve every development team’s problems.
https://netflixtechblog.com/full-cycle-developers-at-netflix-a08c31f83249

Pipeline for different applications is a common demand for software engineering, data engineering and data scientist. It can also help business developers focus on their business logic, and a centralized team can support the most updated stacks in the big organization.
A pipeline is a code. So how can we share and combine pipeline code with the business code quickly and smoothly? This article will share 3 patterns and anti-patterns with Jenkins features to achieve this goal. However, it does not limit you to using modern CI/CD tools like cloud pipelines like Azure Pipelines, AWS CodePipeline, Google Cloud build.
Patterns:
- To set boundaries and separate responsibilities. Let specialists do the professional job.
- Centralized pipelines in a centralized git repository, a centralized team to maintain, update and bug fix. CI can combine the various source code, pipeline and deployment in one building process.
- To give the possibility and flexibility to the end developer to customize features and add new ideas.
Anti-Patterns:
- Anyone can do anything. I am not sure whether it is good or bad, but asking data scientists to write a service deploy pipeline is too expensive, opposite asking DevOps to write an NLP pipeline is also challenging.
- Each project has its pipeline. How to fix >100 repositories with the same legacy pipeline simultaneously? Don’t repeat yourself.
- Control over Innovations. A centralized team does not have the capacity or passion for taking the responsibilities. Then the mess is coming, in the organization better have a mature-approve model to control innovation instead of killing the invention.
Economy effects
Depending on your organization size, if there are 1000 developers, each team has over 10 projects running on the production like today’s modern microservice pattern. And the pipeline bug fix needs 2 hours for a specialist, and a general developer needs to invest time to understand the context and solve it for 4 hours at the first time. Others same pipeline can be solved in 1 hour with previous experience.
Hour(x) = 1000(developers) x ( 1 (first project) x 4(hour) + 9(other projects) x 1(hour))
= 1000 x( 1 x 4 + 9 x 1)
= 13,000 h
Using Germany Munich Average Developer’s Salaries € 7000/Month
Cost(x) = 13000(h) x 7000(€)/22(D)/8(H)
= 13000 x 7000 /22/8
= 517, 045 €
In scaling economy, one specialist fixes a bug in the centralized repository pipeline, can save half a million for 2 hours consumed bug in 1000 developer’s organization.
Let’s do it in action.
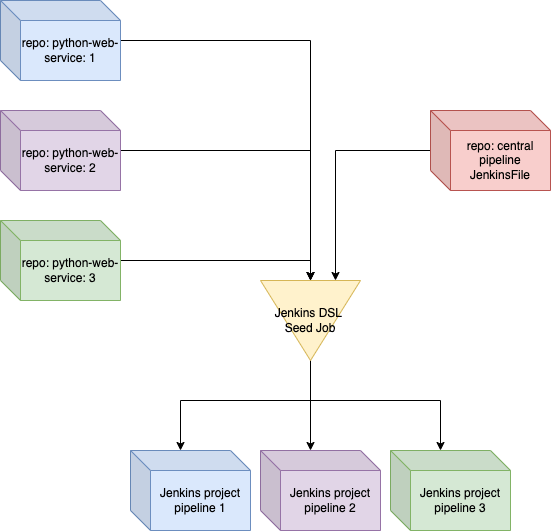
Use case: build a pipeline that can support python flask web service, which can deploy to Azure Kubernetes service.
- Create two repositories, one for source code one for pipeline code.
- To use Jenkins DSL to create a similar pipeline for the same type of workflow with parameters, like spring boot application, python web application, etc…
- ocr_service is classic python flask web service
- Combine pipeline code and source code in the same CI job
//github server setting
String github_token_credential = "git-token-credentials"
String github_host = "github.com"
//central pipeline repository
String pipeline_repository = "wuqunfei/jenkins_ai_pipelines"
String pipeline_jenkins_file = "Jenkinsfile.py.aks.groovy"
//application source code
String source_code_repository_url = "https://github.com/wuqunfei/ocr_service"
String source_code_branch = "main"
//Azure ACR and AKS
String acr_name = "ocr"
String acr_credential = "acr_credential"
String aks_kubeconfig_file_credential = "k8s"
//Application
String application_name = "pysimple"
pipelineJob("ocr-service-builder") {
parameters {
stringParam('github_token_credential', github_token_credential, 'Github token credential id')
stringParam("application_name", application_name, "application_name for docker image")
stringParam("source_code_repository_url", source_code_repository_url, "Application Source Code HTTP URL")
stringParam("source_code_branch", source_code_branch, "Application Source Code Branch, default main")
stringParam("pipeline_repository", pipeline_repository, "pipeline github project name")
stringParam("pipeline_jenkins_file", pipeline_jenkins_file, 'pipeline file')
stringParam("acr_name", acr_name, "Azure Container Registry name for docker image")
stringParam("acr_credential", acr_credential, "Azure Container credential(user/pwd) id in jenkins ")
stringParam("aks_kubeconfig_file_credential",aks_kubeconfig_file_credential, "Azure AKS kubeconfig file credential id in Jenkins" )
}
definition {
cpsScm {
scm {
git {
remote {
github(pipeline_repository, "https", github_host)
credentials(github_token_credential)
}
}
}
scriptPath(pipeline_jenkins_file)
}
}
}
Jenkins DSL API https://jenkinsci.github.io/job-dsl-plugin/#path/pipelineJob

pipeline {
agent any
stages {
stage('Checkout Source Code and Deployment Code') {
steps {
echo "Checkout source code done ${source_code_repository_url}"
git branch: "${params.source_code_branch}", credentialsId: "${params.github_token}", url: "${params.source_code_repository_url}"
echo "Checkout source code done ${source_code_repository_url}"
}
}
stage("Test Code"){
steps{
echo "Test code"
}
}
stage("Build Code"){
steps{
echo "application build done"
}
}
stage("Docker Build"){
steps{
script {
dockerImage = docker.build("${params.application_name}:${env.BUILD_ID}")
}
echo "docker build done"
}
}
stage("Docker Publish ACR"){
steps{
script{
docker_register_url = "https://${params.acr_name}.azurecr.io"
docker.withRegistry( docker_register_url, "${params.acr_credential}" ) {
dockerImage.push("latest")
}
}
echo "docker push done"
}
}
stage("Kubernetes Deploy"){
steps{
withCredentials([kubeconfigContent(credentialsId: 'k8s', variable: 'kubeconfig_file')]) {
dir ('~/.kube') {
writeFile file:'config', text: "$kubeconfig_file"
}
sh 'cat ~/.kube/config'
echo "K8s deploy is done"
}
}
}
stage("Service Health Check"){
steps{
echo "Service is up"
}
}
}
}
The implementation is straightforward, but letting the team members and manager comprehend takes much more time. One of my working companies took at least two years to mature this idea, with some fantastic architects pushing the idea “pipeline driven organization” https://www.infoq.com/articles/pipeline-driven-organization/.
I hope my experience can inspire anyone to apply to your organization with Jenkins or other cloud CI/CD tools.
Reference is here:

Leave a comment