Business is constantly changing. How to design a scalable python application in the data scientist and data engineering world?
It is no one mature enterprise-level framework in python data world compared Java’s Enterprise frameworks like springboot, microprofile, etc…. but I try to use dependency Injection and configuration pattern to clean python code.
Use Case
There is a nlp processing in financial project, but with more different business case in need, configuration and dependencies becomes overwriting and missing conf or cyclic dependency in python.
We build an NLP example service following the dependency injection principle. It consists of several services with a NLP domain logic. The services have dependencies on database & storage by different providers. In the meanwhile, the configuration can also be Inheritance by python @dataclass and supported hydra.cc framework.
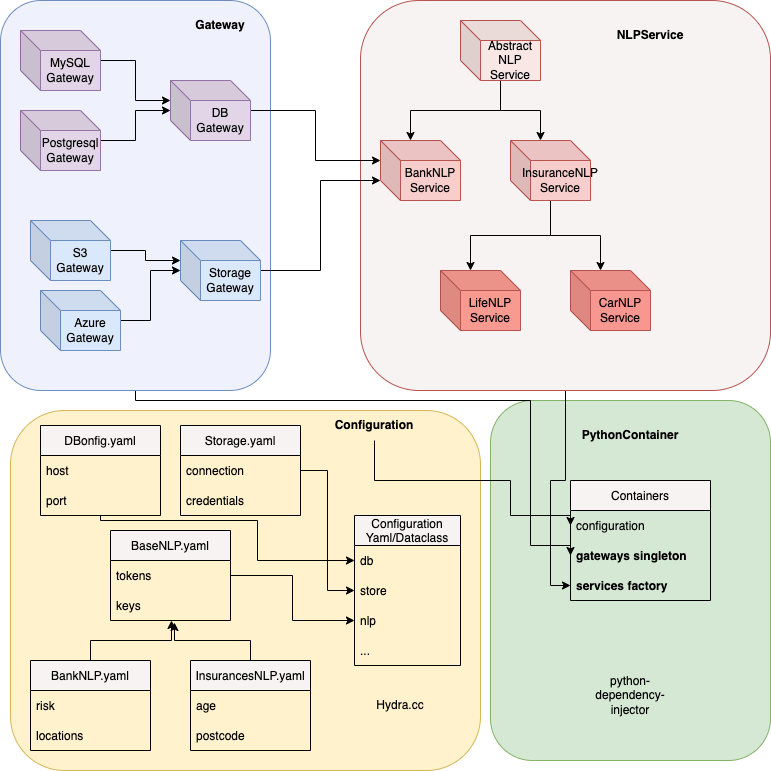
Refactoring
high cohesion and loose coupling recap.
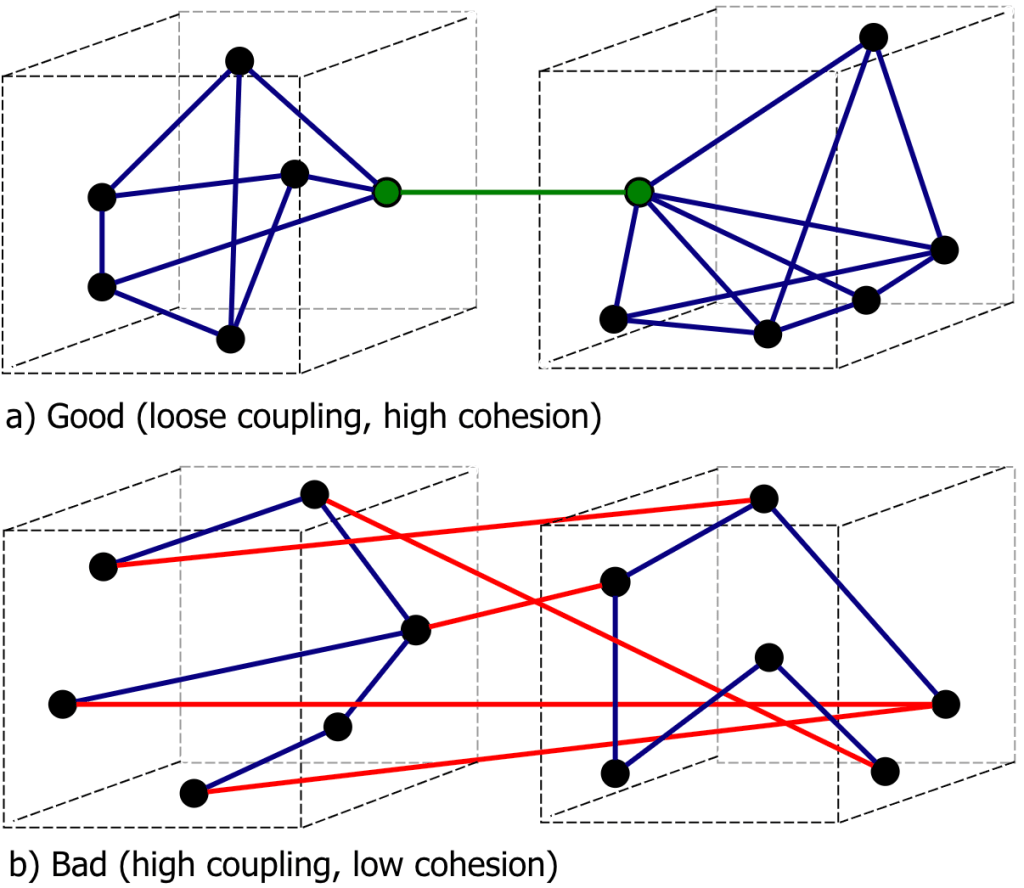
1. Coupling is the degree of interdependence between software modules, tightly coupling modules can be solved by dependency Injection pattern.
2. Complicated Configuration can be extend, validate, Inheritance by Hydra.cc and pydantic framework.
Configuration
Assembling Processing
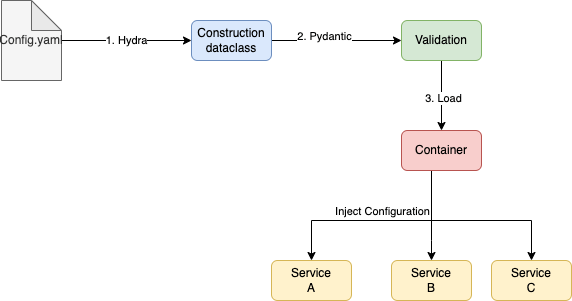
there are 3 main steps to handle configurations
- Load configuration from YAML into python dataclass by Hydra.cc framework which developer by facebook team.
- Using Pydantic library’s annotation(@validate) to check the value of your configuration
- Set the configuration into container, container injects this configuration into different services easily. DI library called python dependency injection
from pydantic import validator
from pydantic.dataclasses import dataclass
@dataclass
class MySQLConfig:
driver: str
user: str
port: int
password: str
@validator('port', pre=True)
def check_port(cls, port):
if port < 1024:
raise Exception(f"Port:{port} < 1024 is forbidden ")
return port
Personally experience, I prefer to dataclass instead of pydantic BaseModel. In fact pydantic has pydantic.dataclasses which looks like dataclass and support @valiator annotation.
Extra read, I only use simple config in demo case. If you like to extend the complicate and separate YAML, please check in detail https://hydra.cc/docs/tutorials/structured_config/hierarchical_static_config/ like this
from dataclasses import dataclass
import hydra
from hydra.core.config_store import ConfigStore
@dataclass
class MySQLConfig:
host: str = "localhost"
port: int = 3306
@dataclass
class UserInterface:
title: str = "My app"
width: int = 1024
height: int = 768
@dataclass
class MyConfig:
db: MySQLConfig = MySQLConfig()
ui: UserInterface = UserInterface()
cs = ConfigStore.instance()
cs.store(name="config", node=MyConfig)
@hydra.main(config_path=None, config_name="config")
def my_app(cfg: MyConfig) -> None:
print(f"Title={cfg.ui.title}, size={cfg.ui.width}x{cfg.ui.height} pixels")
if __name__ == "__main__":
my_app()
Hydra is quite impressive by its feature, you can check this youtube video “Configuration Management For Data Science Made Easy With Hydra“
Application Structure
./ ├── src/ │ ├── __init__.py │ ├── containers.py │ ├── gateway.py │ └── services.py ├── config.yaml ├── __main__.py └── requirements.txt https://github.com/wuqunfei/python-di-config
Gateways
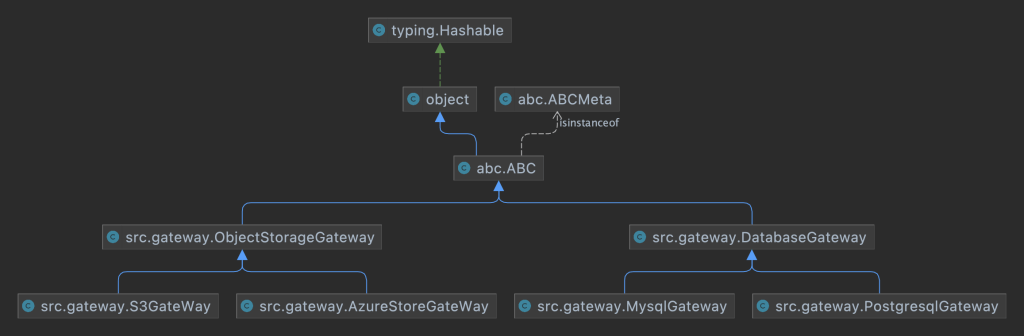
from abc import ABC, abstractmethod
from loguru import logger
class DatabaseGateway(ABC):
def __init__(self):
...
@abstractmethod
def save(self):
...
class MysqlGateway(DatabaseGateway):
def __init__(self):
...
def save(self):
logger.info("Saved in Mysql")
class PostgresqlGateway(DatabaseGateway):
def __init__(self):
...
def save(self):
logger.info("Saved in Postgresql")
class ObjectStorageGateway(ABC):
def __init__(self):
...
@abstractmethod
def download(self):
...
class S3GateWay(ObjectStorageGateway):
def download(self):
logger.info("download from AWS S3 blob Storage")
class AzureStoreGateWay(ObjectStorageGateway):
def download(self):
logger.info("download from Azure Object Storage")
Services
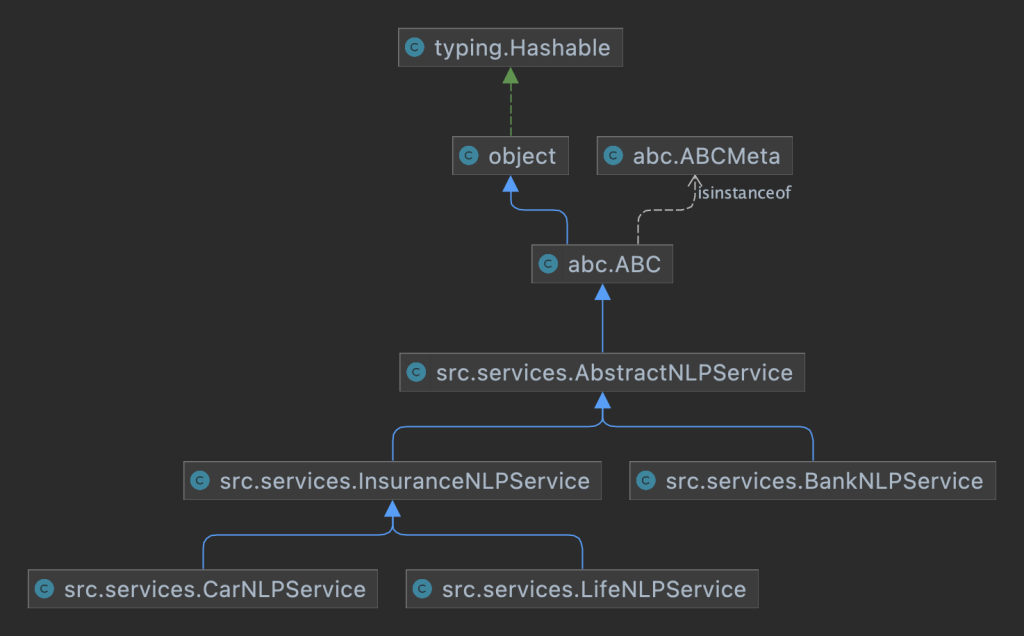
from abc import ABC, abstractmethod
from loguru import logger
from src.gateway import DatabaseGateway, ObjectStorageGateway
class AbstractNLPService(ABC):
def __init__(self, config: dict):
self.config = config
@abstractmethod
def ocr_preprocess(self):
...
@abstractmethod
def tokenizer(self):
...
@abstractmethod
def chunker(self):
...
@abstractmethod
def post_process(self):
...
def run_nlp(self):
self.ocr_preprocess()
self.tokenizer()
self.chunker()
self.post_process()
class BankNLPService(AbstractNLPService):
def __init__(self,
config: dict,
db_gateway: DatabaseGateway,
storage_gateway: ObjectStorageGateway):
super().__init__(config)
self.db_gateway = db_gateway
self.storage_gateway = storage_gateway
def ocr_preprocess(self):
self.storage_gateway.download()
logger.info(f"{self.__class__.__name__} OCR preprocess done")
def tokenizer(self):
logger.info(f"{self.__class__.__name__} Tokenizer done")
def chunker(self):
logger.info(f"{self.__class__.__name__} Chunker done")
def post_process(self):
logger.info(f"{self.__class__.__name__} post process done")
logger.info(self.config)
self.db_gateway.save()
class InsuranceNLPService(AbstractNLPService):
def __init__(self, config: dict):
super().__init__(config)
def ocr_preprocess(self):
logger.info(f"{self.__class__.__name__} OCR preprocess done")
def tokenizer(self):
logger.info(f"{self.__class__.__name__} Tokenizer done")
def chunker(self):
logger.info(f"{self.__class__.__name__} Chunker done")
def post_process(self):
logger.info(f"{self.__class__.__name__} post process done")
@abstractmethod
def get_risk(self):
...
class LifeNLPService(InsuranceNLPService):
def get_risk(self):
logger.info(f"{self.__class__.__name__} risk score 1.0 done")
class CarNLPService(InsuranceNLPService):
def get_risk(self):
logger.info(f"{self.__class__.__name__} risk score 2.0 done")
Container
class MyContainer(containers.DeclarativeContainer):
config = providers.Configuration()
'''Gateways as singleton'''
mysql_gateway: DatabaseGateway = providers.Singleton(
MysqlGateway
)
s3_gateway: ObjectStorageGateway = providers.Singleton(
S3GateWay
)
'''Services factory '''
nlp_service_factory: AbstractNLPService = providers.Factory(
BankNLPService,
config=config,
db_gateway=mysql_gateway,
storage_gateway=s3_gateway
)
life_nlp_factory: AbstractNLPService = providers.Factory(
LifeNLPService,
config=config
)
car_nlp_factory: AbstractNLPService = providers.Factory(
CarNLPService,
config=config
)
Main Function
Let’s put all together and run it
@hydra.main(config_path="", config_name="config")
def my_app(cfg: MySQLConfig) -> None:
"""1. to get config yaml by hydra"""
cfg_dict = dict(cfg)
"""2. to validate the configuration by pydantic"""
MySQLConfig(**cfg_dict)
container = MyContainer()
"""3. to load configuration into container"""
container.config.from_dict(cfg_dict)
nlp = container.nlp_service_factory()
nlp.run_nlp()
if __name__ == "__main__":
my_app()
Finally Results
2022-02-10 20:11:59.873 | INFO | src.gateway:download:43 - download from AWS S3 blob Storage
2022-02-10 20:11:59.873 | INFO | src.services:ocr_preprocess:48 - BankNLPService OCR preprocess done
2022-02-10 20:11:59.873 | INFO | src.services:tokenizer:51 - BankNLPService Tokenizer done
2022-02-10 20:11:59.873 | INFO | src.services:chunker:54 - BankNLPService Chunker done
2022-02-10 20:11:59.873 | INFO | src.services:post_process:57 - BankNLPService post process done
2022-02-10 20:11:59.873 | INFO | src.services:post_process:58 - {'driver': 'mydriver', 'user': 'root', 'port': 3306, 'password': 'foobar'}
2022-02-10 20:11:59.873 | INFO | src.gateway:save:20 - Saved in Mysql
It is a simple practise to clean python code with 3 libraries
- https://python-dependency-injector.ets-labs.org/
- https://hydra.cc/docs
- https://pydantic-docs.helpmanual.io/usage/dataclasses/
Source Code address, hope it inspires us to write clean python code.
git clone git@github.com:wuqunfei/python-di-config.git

Leave a comment